How to use hash functions for split test assignment
Hash-based user assignment brings experimenters many benefits in running split tests. It's used extensively in the industry (section 4.1.2, page 6), at companies like LinkedIn, Google, Microsoft and many others. Compared to the ephemeral random numbers generated from PRNGs, hash-based decisioning gives you far greater control:
- Consistent assignment across devices & platforms
- Retroactively "track" users assigned/excluded but not tracked
- Exclude users who may have been exposed during your canary release (aka. partitioned ramps)
- The ability to "back-test" your assignment before launching (e.g. see which treatment groups the last 30 days' users would have seen)
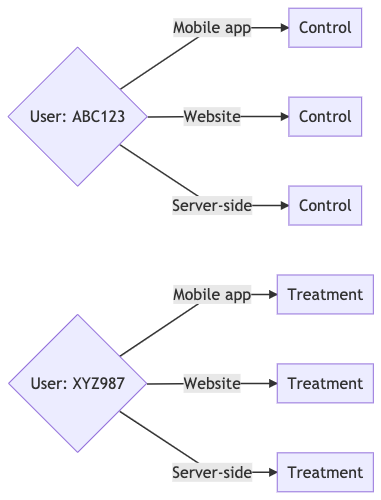
As long as you have a consistent user ID across platforms, users will be bucketed the same way everywhere.
You'll be amazed how simple this is.
How it works
In Mojito, we turn a hash function's digest into a PRNG by:
- Calculating the hash digest of the
user ID+test salt - Converting the resulting hex digest into an integer & dividing by the largest number in the space for a decision between
0and1 - Applying the resulting decisions to the user being bucketed
decision < 0.5 ? control() : treatment()
The meta discussion around cryptographic hash functions === PRNGs is beyond the scope of this article, but there's a lot of discussion in the literature about why this works. And there's also some approachable Stack Overflow posts that make the case for Hash-based PRNGs.
Also, it's worth noting some tools calculate the modulo of the hex digests' integer. However due to our variable recipe sample rates, we need to supply a value between 0 and 1.
Hash functions
If you're unfamiliar with hash functions, like MD5/SHA256 etc, their purpose is to distill your input data down to a fixed-length hexadecimal string. It works like this:
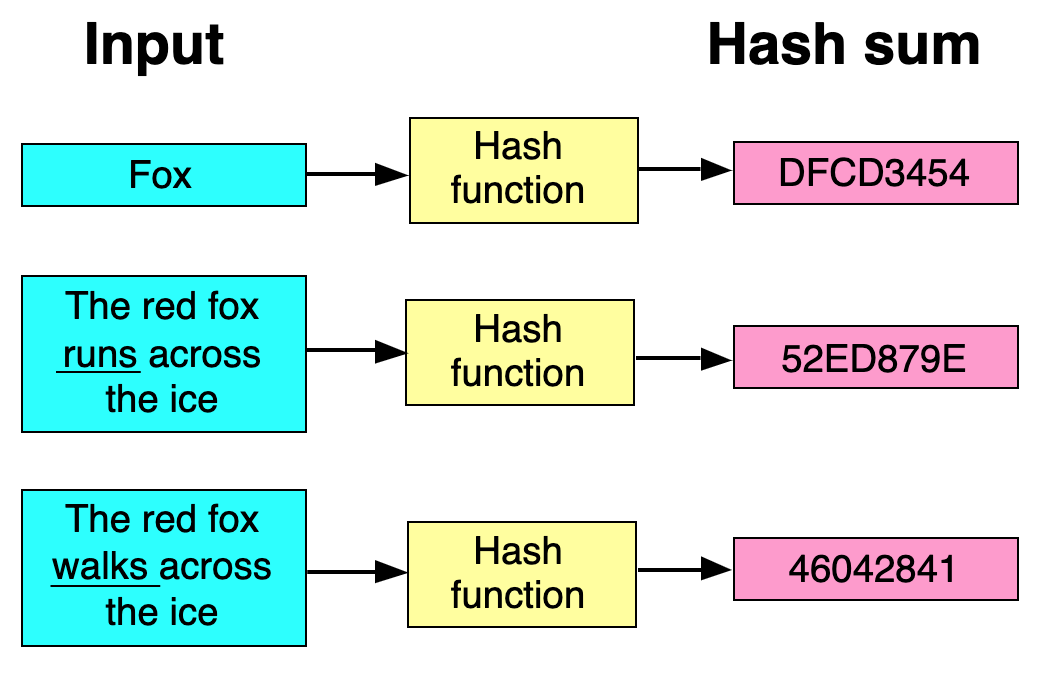 Image credit: David Göthberg, Sweden / Wikipedia.
Image credit: David Göthberg, Sweden / Wikipedia.
And luckily for us, the hexadecimal output can be parsed into numbers we can use for bucketing/assignment.
Using hashes as your PRNG in Mojito
Using a user/cookie ID and Mojito's decisionAdapter, we can control how users are bucketed. We'll take the user/cookie ID and send it through a hashing function to deterministically generate a really solid random numbers between 0 and 1:
1. Hash the user's ID & the experiment's salt
Each time you generate a hash from a seed, you'll get the same result. For our purposes we use MD5 as the hashing function because its properties make it well-suited to a split testing.
var userId = '1234567';
var testSalt = 'ex3';
var seed = userId + testSalt;
// result: '1234567ex3'
var md5Hash = Mojito.utils.md5('1234567ex3');
// result: '404c9f9d26876611359c2a6472012d53'
2. Generate the decisions for an experiment
We can derive psuedorandom numbers from the hexadecimal values of the hash digest 404c9f9d26876611359c2a6472012d53, like so:
parseInt('404c9f9d', 16);
// result: 1078763421 (0x404c9f9d)
parseInt('404c9f9d', 16) / 0xffffffff;
// result: 0.25116918172016023
For each test, we need to make 2-3 decisions. And each decision uses a quarter of the hash digest:
- Test sample rate:
0x404c9f9d / 0xffffffff->0.25116918172016023 - Recipe assignment:
0x26876611 / 0xffffffff->0.15050352019036736
Each 'decision' is capable of producing over 4 billion values - more than enough granularity for our purposes (it's probably overkill). More 'secure' hash functions exist, but we only need speed & reliability. We picked it because MSFT/LinkedIn et al use it, MD5 digests are pervasive across DBs/languages, and from our testing at Mint Metrics, it produces nice flat & even distributions:

3. Use the 'decisions' in your assignment
Consider the following experiment:
state: live
sampleRate: 0.5
id: ex3
name: Homepage button
recipes:
'0':
name: Control
sampleRate: 0.1
'1':
name: Treatment
sampleRate: 0.9
trigger: trigger.js
And taking the example decisions from the user above, we know the decisions they will get:
- Test sample rate:
0.251... < 0.5-> Included in test - Recipe assignment:
0.15... > 0.1-> Assigned toTreatment
No matter when/where this user is bucketed (e.g. app/web/server) they will always get the same decisions because of their user ID.
Apply it in Mojito
Hopefully, this gets you excited about using hash functions in your split tests.
Mojito users can swap out our default decisionAdapater with their own hashing functions and logic. Don't like MD5? Go with SHA-256! Prefer adding more salt? It's up to you.
See the API reference for the decision adapter for more details and to implement your own.